
The SQL on Hadoop capability is turning out to be a real game changer for data warehouse and Hadoop vendors. To get a sense of what is happening in this intriguing space, Sachin Ghai talked to Emma McGrattan about SQL on Hadoop solutions. Emma is the Senior Vice President for Engineering at Actian and has the responsibility for analytics platform. In this 2 part interview published on HadoopSphere, Sachin asked Emma questions about the generic SQL on Hadoop ecosystem and got further technical insights into market space and technical architecture. Read more to understand about SQL on Hadoop solutions (or SQL 'in' Hadoop as Actian likes to term it).
What is the state of Hadoop ecosystem at this time? Where does it seem to be heading particularly with regards to SQL on Hadoop solutions?
If I could point you to SQL in Hadoop landscape (graphical image), that is a good slide to use to explain where we see landscape today and what we see as the future plans for some of the competitors in the space and how we position ourselves here. First off, if you look at the slide at the axis we use, the Y axis here is the product maturity. People have expectations when they are running SQL solutions and these are expectations that they've built up over the past decades because of experience with traditional enterprise data warehouse technologies and traditional relational database technologies. And so when you're dealing with the SQL language, there is an assumption that there's going to be the full language support and you're going to have the ability to run transactions.
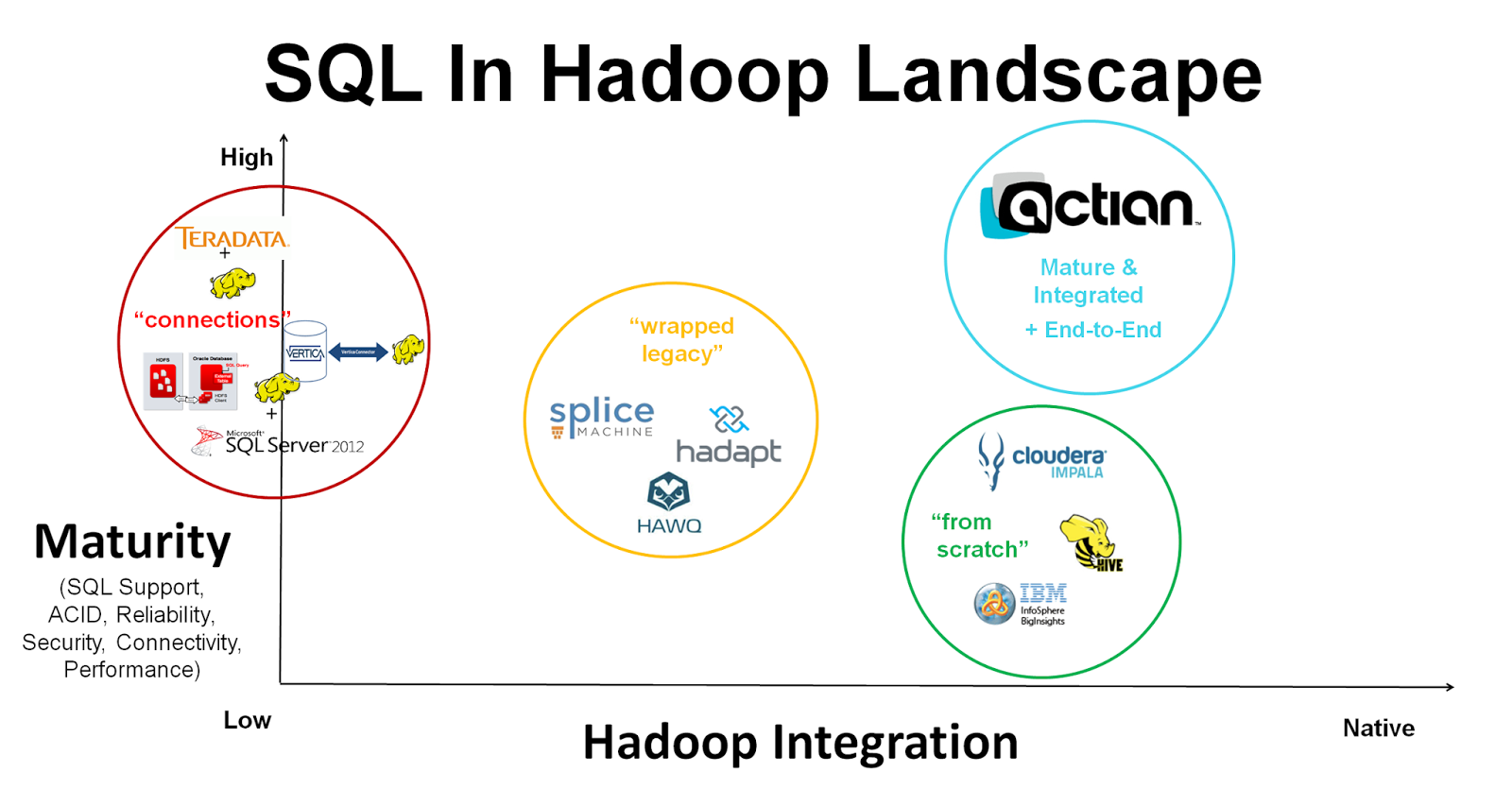 |
| SQL in Hadoop landscape as per Actian |
Let's say take a very simple transaction such as transferring $100 for my checking account to my savings account I don't want to debit the checking account unless I know the savings account can be credited by that $100. So the idea of a transaction is something that's fundamental to people using databases and the ability to roll those back. Let's say I have made a mistake and I can't actually update my savings account, I will be able to roll back that transaction. These are ideas that people have that a database should provide and the SQL in Hadoop players because of their lack of maturity they don't have all of these features.

On the maturity axis here we're looking at things like the language support capabilities and the security features that they provide their performance. So we look at this first circle that we've got on the graph here. We've got the traditional enterprise data warehouse players - so this is Teradata, Oracle, SQL Server 2012 and its Vertica. What these guys are doing they're trying to protect the revenue that they get from traditional enterprise data warehouses. These are public companies and have shareholders whose interests need to be protected. So they need to protect their revenue streams and what these guys are typically doing is they're continuing to push the enterprise data warehouse for the analytics needs. What they're doing is recognizing the fact that people are storing new data types and new data sources in Hadoop. So they provide connectors through to the Hadoop environment and which is why in the red title for this box, I have called them “connections”. What they do is they connect to data in Hadoop and they pull that data from Hadoop into the traditional enterprise data warehouse and they allow you to operate on it. So these guys are really not in Hadoop and they provide connections through to Hadoop data source and I believe that they provide a lot of the capabilities that one will expect in enterprise data warehouse.
The next circle on here is “wrapped legacy” circle. These companies have taken a traditional relational database technology from the open source world - typically it's a Postgres although in the case of Splice Machine it's Apache Derby. What they've done is they're using the SQL capability of these and all of the capabilities that these legacy database solutions provide and then they are converting SQL statements in MapReduce jobs or finding some way of executing those queries on data resident in Hadoop. In terms of their maturity, they have a lot of capabilities because they've taken mature database technologies. But some of the capabilities that one would expect in terms of performance and scalability - they don't have that because under the underlying capabilities that they take from Hadoop such as MapReduce, just don't perform. They inherit capabilities that lack performance from underlying Hadoop capabilities.
And third circle in here this green circle table what we label as “from scratch” players and this is the likes of Cloudera Impala, Hortonworks Hive or the IBM Big Insights. What these guys have done is they have built a solution from scratch specifically for Hadoop. They're not cannibalizing any other technologies. They started out with a clean sheet and they're looking to build capabilities that are native to Hadoop. So in terms of the X-axis here, they are very well integrated with Hadoop. But because they're being built from scratch, they're lacking all of the material that one expects from SQL on Hadoop solutions. Security is something that they're kind of bolting on up to the fact; performances is very poor and then they are missing some capabilities like the ability to perform updates. So if you want to have an individual record within a dataset updated these guys have really struggled how best to do that. For those solutions that have figured out how to do updates, they sacrifice performance on the rest of the queries - so that's something that you really lacking in terms of database maturity. But they're very tightly integrated with Hadoop.
What we see as unique about what we do in our own separate circle on the graph is that we've got all of the capabilities that one expects in the traditional enterprise data warehouse. We've got the performance that one expects a traditional enterprise data warehouse and in fact we can outperform the traditional enterprise data warehouse even though we are on Hadoop. We're also very tightly integrated with Hadoop; we use HDFS for file storage and we use YARN for scheduling and failover capabilities and so on. We're very integrated with the Hadoop system but we are able to provide the capabilities that one often has to sacrifice when looking at a SQL on Hadoop solution. Specifically, security is something that a lot of these SQL on Hadoop solutions are lacking and specifically around the ability to update individual records - the capability that's known in the database word as 'trickle updates'. Bulk update is something that everybody can do but the ability to update individual records something that's difficult in Hadoop. The reason it's difficult is that the HDFS file system was designed so that you write data to the file system once and you only ever read it after that. HDFS as a file system wasn't designed for people to be frequently updating the records in there. It just wasn't the design point that they started with and that's why Cloudera is now looking at Kudu. So that they're looking at a completely different implementation because they just can't get HDFS to provide the capabilities that they need.
Now we at Actian have figured out how to do this and we have a patent pending on the capability to do it. Essentially we keep track of changes and we keep track of the positions of data that's changed in the environment in the memory overlay structure. When you reference data that has been updated, we reference this overlay structure and we are able to figure out if the data that you need has changed. As you query the data, you will get the updated value of the result that is passed back to you. Now I can’t go into too much detail as to exactly how we've done this because I say a patent is pending and we do believe when we look at what Cloudera is doing in Kudu, they have borrowed a number of the ideas - because up until now we have been talking about this publicly and the Cloudera guys have learned a lot from development work and research work that we have done at Actian.
And that's how we see the landscape - provide all of the capabilities on the maturity that one expects from the traditional enterprise data warehouse. We are also very tightly integrated with Hadoop using all of the Hadoop projects that can benefit an enterprise data warehouse like the file system and like YARN resource negotiation.

One of the key trends that is emerging is that most of the SQL on Hadoop solutions are beginning to support ACID transactions and in fact Hive has started supporting ACID transactions in 0.14 release. But most of these solutions are still of OLAP nature. Do you see these solutions moving towards OLTP support or is that still a pipe dream?
Splice machine today supports OLTP and that's their target right now. They don't do analytics so much as they do OLTP and when they talk about their performance they used the TPCC benchmark which is a well-known OLTP benchmark to demonstrate their capabilities. I think the challenge that all of the players have in supporting the OLTP workload is the fact that the underlying filesystem just was not designed for it. There's a couple of things that get in the way: obviously if it's not designed for supporting random updates to the data and then taking a very heavy update intensive workload to file system is going to be a nightmare for disaster. That requires capabilities like we've had to implement whereby you actually keep track of all of the changes in memory and you have a Write Ahead Log file because you need that consistency that ACID guarantees. Should you lose power in your data center and the cluster disappears you want to make sure that any of the transactions that were committed at that point in time can be recovered during the cold start recovery process. I think projects like Kudu will help but I think there's a fundamental problem with the underlying distributed file system in Hadoop that is causing a real challenge for bringing OLTP workloads to Hadoop.
Another key question which most customers come up is that how difficult or easy is it for them to migrate the legacy SQL and ETL workloads they were running in the traditional warehouse to the big data warehouse. What has been your experience in getting those SQL workloads migrated to the big data clusters?
When I talk about the guys that are lower on the SQL maturity scale, two things that they're missing. One is the full SQL language support so they will have a very limited subset of SQL language implemented and that is a problem when taking existing workloads to Hadoop. The reason for that is that traditional workloads most times use off-the-shelf tools for generating reports and dashboards and so on. You don't have control over exactly what syntax is going to be produced by those tools - so that you cannot then work around deficiencies in their SQL implementations. That's the first challenge they face and they're trying to round out their SQL language support. The 'from scratch' and 'the wrapped legacy' players don't have a complete language implementation. For the 'from scratch' guys, it's just because they haven't had the time to complete it yet and for 'the wrapped legacy' guys it's because the underlying capabilities that they're depending upon don't provide everything. So you know it may be that they're taking SQL and then converting to MapReduce jobs - so they don't get the full capabilities that one needs for supporting these traditional workloads.
The second challenge that these 'from scratch' players is that their query optimizers are very immature. If you look at Hive or Cloudera and look at how they optimize queries. They don't have the smarts to figure out what's the best order in which the tables were you referencing multiple tables within a query. To work around that limitation, what they do is that they require that you list the tables in the order which you want them joined. As you write the SQL as an application developer, you need to know which is going to be the most efficient join order of the tables and you need to code that in query. As I said earlier, traditional workloads used tools like Business Objects, Tableau and any visualization technology. You don't have control over SQL that they're generating and so you don't have control over things like join orders. That's a real challenge and when we look at the 'from scratch' players and the 'wrapped legacy' players they really struggle to take traditional enterprise data warehouse workloads to Hadoop using those technologies.

With the Actian solution, we have the complete SQL language implementation and we also have invested many decades in optimization technologies. What we were able to do is to take our Cost Based Query Optimizer to Hadoop and modify it for some of the unique scenario that one encounters in Hadoop. We can outperform the competition on Hadoop by quite a margin if you look (at the performance benchmark diagram). You'll see here is that when we compare our performance with that of Impala and if you read this graph correctly it's a little confusing. What we did was we took a workload that the Impala team used to demonstrate their superiority over Hive. They ran these queries and said that they were 100 times faster over Hive. What we did was we ran them against the Actian SQL in Hadoop and we show for instance for first query, we are 30 times faster than Impala.
We can outperform these guys by quite a margin because we know how to solve complex queries and we also can take a standard EDW workload and deploy it on Hadoop without having to change anything. We have some very large customers and that were previously off Hadoop with our Vector technology. We moved them to Vector on Hadoop and without changing anything except the connection string where they pointed to the database they were able to run their enterprise data warehouse workload against SQL in Hadoop solution. Being able to do that for a customer is very exciting, it's very empowering and for us it means certifying the latest versions of Cognos or Informatica or whatever it may be. We certify them as part of our standard QA process and we know that any customer that's using any official tool for EDW today can move their workload to our SQL in Hadoop solution without having to compromise performance or functionality or security.
That's pretty interesting and these benchmarks are often talking points since they hide more than they show.
That is a good thing that you raised...You'll see that the SQL that we use in Vector is a standard SQL. These benchmarks typically what they are measuring is the performance at the database engine - so they usually will restrict to 100 rows that come back from the query. Those top 100 rows from three tables that we're going to join and then we've got some join conditions here and some group by and order by. If you look at... the Impala equivalent in their benchmark capability, what they actually do is they specify the partition keys that are used for solving this query. They have completely cheated in this benchmark. They know exactly where on disk the rows that are gonna satisfy the query lie and they point exactly to those rows. But even with them playing that trick, we will outperform them by thirty times.

The benchmarks are not something that I would trust unless they came from a party like TPC and they are audited benchmarks. In this particular case that we call as the Impala subset of TPC-DS they identified the queries where they were going to out-perform Hive, they rewrote them because they have limited SQL support and then they added the partition keys. So it's a game - they cheated and I call them on their cheating when I use this presentation publicly because I think it's wrong.
Everybody is playing games with these benchmarks and we can use them to demonstrate whatever you chose. But for us we're using standard SQL. We have clean hands in this and we also plan something for the first half of next year to publish some audited benchmark results. We're not running the TPC-DS because that benchmark is under review with TPC Council right now and it looks like they're going to deprecate it replacing it with something for Hadoop. We are going to take more traditional workload TPC-H benchmark and we are going to publish numbers in first half of next year and these will be audited benchmark numbers for TPC-H benchmark on Hadoop. We will be the first database vendor to publish audited TPC benchmarks for Hadoop. We are very excited by this because our performance is going to be, I hope, an order of magnitude greater than traditional enterprise data warehouse players. We expect to beat Teradata, Oracle, SQL Server and Vertica by an order of magnitude which is huge when you are dealing with Hadoop which is known as commodity workhorse platform but is not known for performance.

Continue reading: Actian Vortex SQL in Hadoop deep dive >>
Comments
Post a Comment